
Introdução
Sabe-se que FPGA é uma tecnologia bastante promissora no momento. Isso acontece porque aconteceram várias situações para que este tema fosse levado a sério tal como a compra da Altera pela Intel, o projeto de pesquisa em FPGA da Microsoft chamado Microsoft Catapult além da combinação de openPOWER com placas da Xilinx. FPGAs são massivamente paralelos, especializados e super conectados tanto internamente quanto externamente com interfaces. Possuem alta vazão de informação juntamente com baixa latência e gasto de energia. Entretanto, atualmente, existem dois desafios que dificultam a relação entre tais mundos:
- A sintetização de projetos em hardware. Não se tem ainda um processo que consiga resultados excelentes de síntese em projetos de grande porte. Como enviar um projeto em C que é modificado todos os dias à placa. OpenCL por exemplo possui suporte à paralelismo mas não consegue manusear com excelência vários modelos de aplicações.
- Compor 100 aceleradores num FPGA com rede de 100 Gb/s e canais DRAM. Seria um procedimento fácil? É possível ver que não é tão simples o mapeamento e suporte.
Phalanx. Um Acelerador De Acelerador
Phalanx é um projeto que foi infraestruturado para fazer aplicações executarem no FPGA de forma facilitada. Consiste no conjunto de Processador + Clusters de Aceleradores + centro de operação de rede.
Sua aceleração requer um processador eficiente e para tal, escolheu-se para o projeto o RISC-V.
Área E Energia
Para obter mais cores dentro de uma mesma área, cada unidade deverá ser simples e pequena. Eliminar recursos não essenciais de cada CPU pode maximizar as áreas gastas de cada core por die. Isso inclui meios como o compartilhamento de unidades de função para o cluster.
GRVI (“Groovy”): Gray Research RISC-V RV*I
Seu propósito é um elemento de processamento paralelo eficiente, suficiente para executar pequenos projetos em C e C++. Escalar com pipeline de 2 ou 3 estágios.
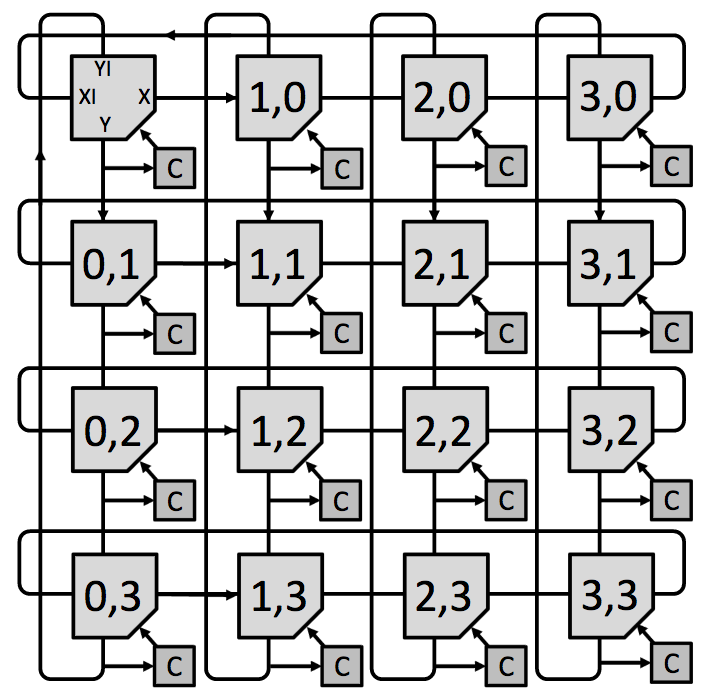
Hoplite 2D Router
Replanejamento de centro de conexão de rede do FPGA tornando a comunicação interna mais simples. É retirado itens que não são essenciais à comunicação e modificado os comutadores de informações entre circuitos para que sejam simples e rápidos.
Abaixo é exibido um diagrama onde cada item possui três entradas e duas saídas formando uma malha. Com isso é eliminado o sistema de buffering
Usando a mesma ideia no FPGA.
Supondo que cada core tem vazão de 256 bits e o sistema possuindo 400MHz, temos um total de 100Gbps.
Implementando um cluster comum em FPGA com 8 processadores, tem-se a seguinte ilustração.
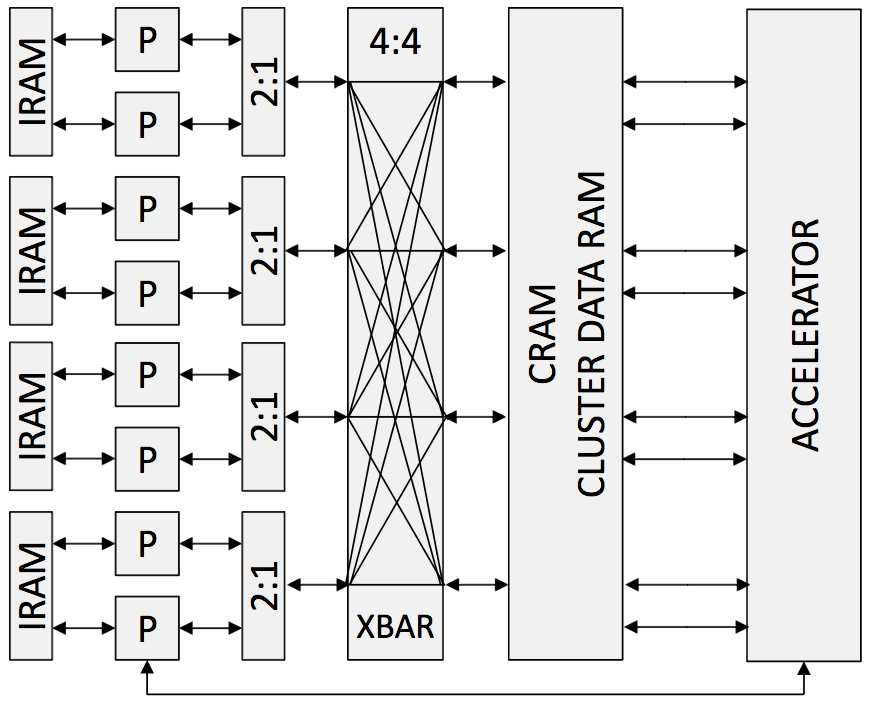
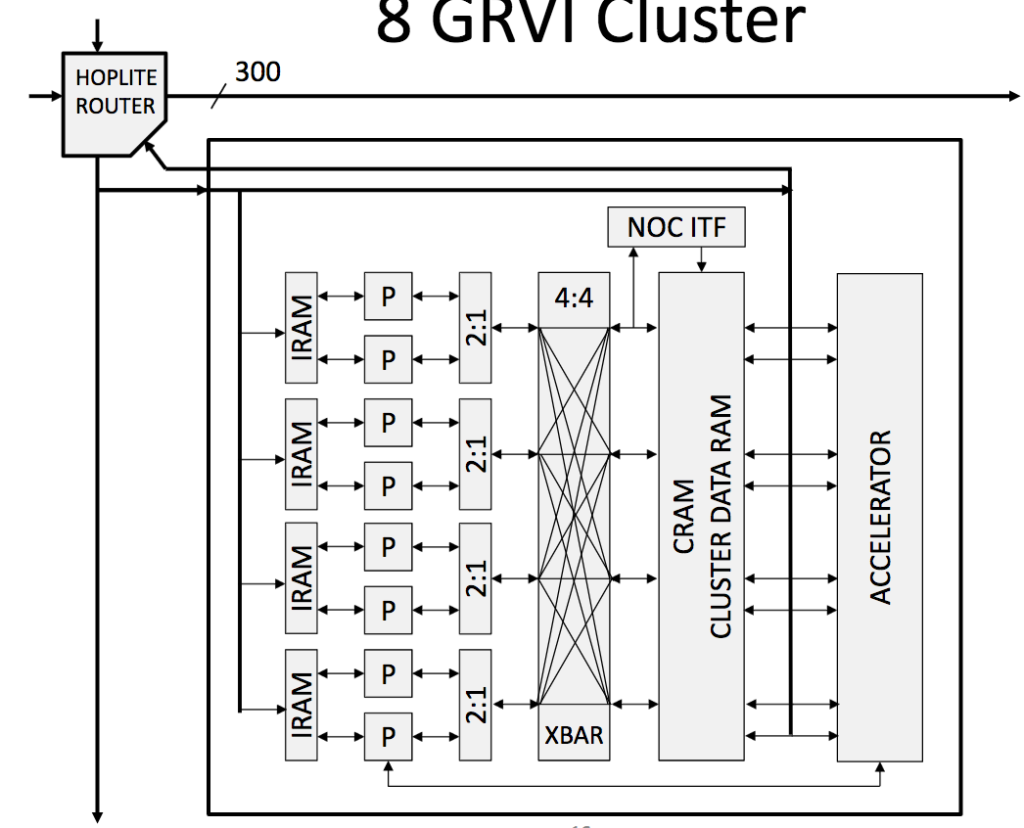
Abaixo é exibido a solução proposta pelo projeto GRVI.
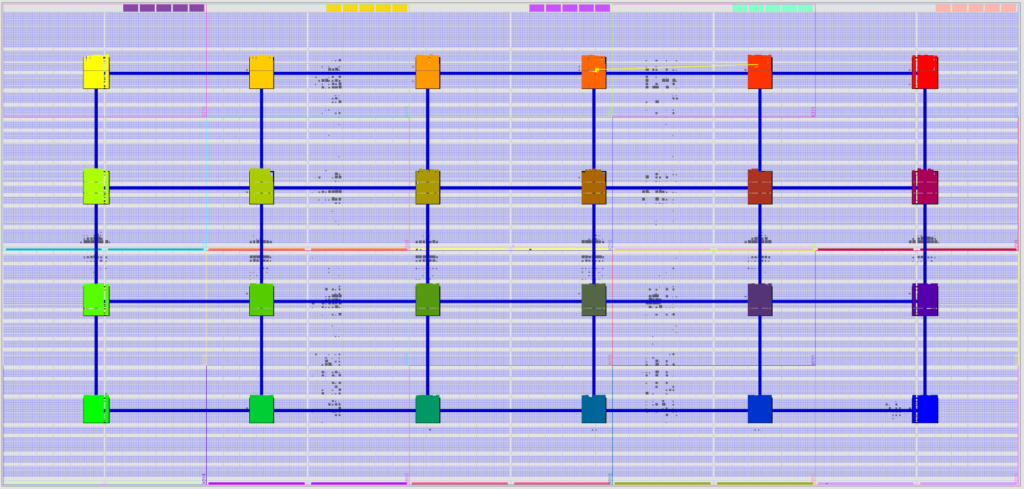
Assim, implementando esta tecnologia num FPGA, preenchendo todo as LUTs disponíveis, temos por exemplo o seguinte resultado.

Cada quadro preto representa um cluster de 8 processadores. Assim, como existe 10 colunas, 5 linhas e cada quadro possui 8 cores, temos então um cluster implementado no FPGA com 400 processadores.
Resumo
GRVI Phalanx é totalmente programável e possui memória local compartilhada e passagem global de mensagens. Possui alta taxa de vazão para I/O e modelos de programação paralela acelerada. Tudo isso conectando via Hoplite NOC.
Summary

Article Name
FPGA como Acelerador em RISC-V Massivamente Paralelo
Description
Assuntos avançados sobre FPGA e aceleradores em embarcados.
Author
Rodolfo Labiapari Mansur
Publisher Name
Laboratório iMobilis
Publisher Logo
Referência: http://www2.decom.ufop.br/imobilis/fpga-como-acelerador-em-risc-v-massivamente-paralelo/


